
自作MIDI音源「CureSynth」製作記事の一覧はこちら
回路図、ソースコードはこちら
前回は、自作MIDI音源「CureSynth」のソフトウェア概要について紹介しました。
今回は、STM32F7+HALライブラリを用い、MIDIメッセージを「USART割り込み」で受信する方法と、受信したMIDIメッセージを蓄積するためのリングバッファについて紹介します。
1.MIDI受信回路
本稿で対象とする回路は、以前作成したvs1053b用の回路を転用し、USART3(RX)に直結しています。以下、USART3をMIDI受信用として話を進めます。
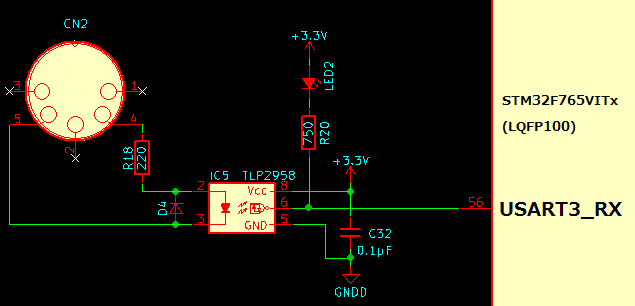
STM32F7VITxのUSART3_RXにMIDI受信回路を接続した図
2.USART割り込みによる受信
2.1.ペリフェラルの設定
USART3をMIDI受信用に設定します。STM32ではペリフェラルの設定がややこしいので、STM32CubeMXを使用すると便利だと思います。説明するのにも、設定画面を載せるのが手っ取り早いですね。たまにバグがあるので、自動生成されたソースコードはよく眺める必要はありますが…
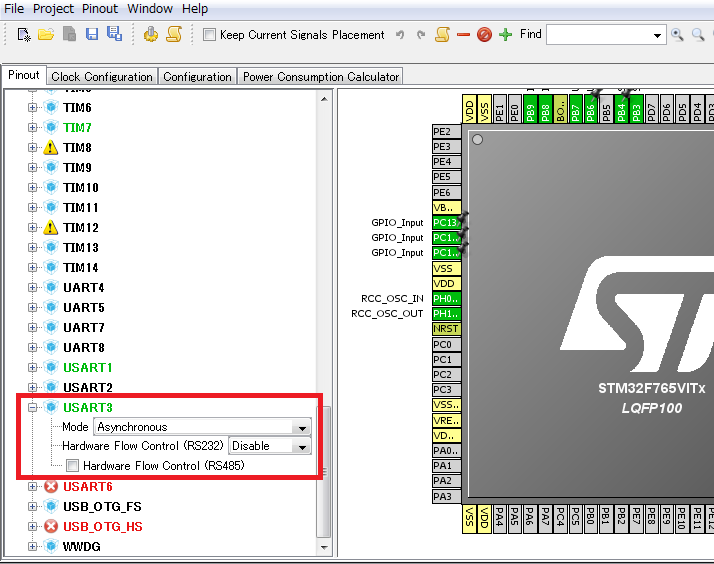
USART3のMIDI受信用の設定 1
STM32CubeMXで、USART3をAsynchronous(非同期)に設定します。フロー制御は行わないためオフとします。
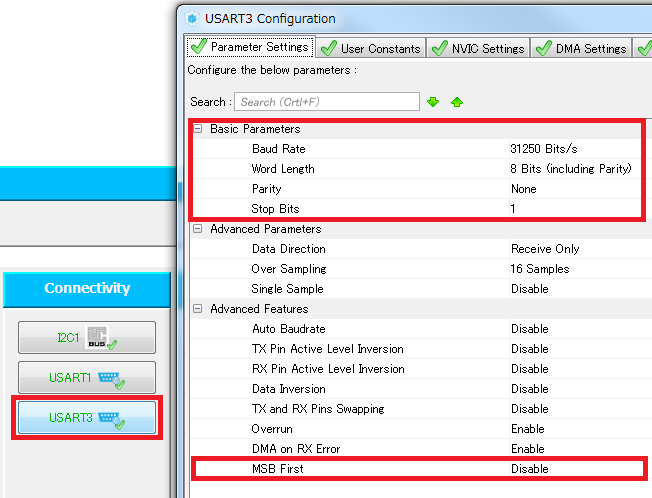
USART3のMIDI受信用の設定 2
ConfigurationタブのUSART3ボタンを押し、Parameter Settingタブの内容を設定します。通信速度を31.25kbps、8bitパリティなし、ストップビットを1(H)にします。MIDIはLSB firstなので、MSB FirstをDisableにしておきます。
MIDIのハードウェアレベルの仕様については、以下の記事がとても読みやすいので、お勧めします。
→MIDI のハードウェアについて(Y-Lab. Electronics, Elekenさん)
余談ですが、STM32のUSARTは、RX/TXの入れ替えや論理の入れ替えなどをハード側でやってくれるので、安心して設計ミスができますね!

USART3のMIDI受信用の設定 3
さらに、NVIC Settingsで、USART3割り込みを有効にしておき、割り込みが発生できるようにします。
以上で設定は完了です。
2.2.実装
USART割り込みのサンプルです。
製作記事その3で示したとおり、MIDIメッセージはバイト単位なので、1バイト(8bit)受信するごとに割り込みが発生するようにします。
また、割り込み処理内でリングバッファ(FIFO)に蓄積し、処理の安定化を図ります。関数cureMidiBufferEnqueue()はバッファへ蓄積する関数です。後述します。
/*main.c*/
//グローバル変数
uint8_t midi_recieved_buf;
//1バイト受信するとコールされる割り込み関数
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
if(huart->Instance == USART3)
{
//受信内容をリングバッファに蓄積する
cureMidiBufferEnqueue(&midi_recieved_buf);
//次の受信に備える
HAL_UART_Receive_IT(&huart3, &midi_recieved_buf,1);
}
}
int main(void)
{
//(中略)
//MIDIメッセージの受信を開始。1バイト受信すると、割り込みを発生させる。
HAL_UART_Receive_IT(&huart3, &midi_recieved_buf, 1);
//(中略)
}
3.リングバッファ
3.1.概念
リングバッファ(循環バッファ)について、MIDIメッセージの受信に必要な概念に限定して説明します。汎用的な内容ついては、以下の記事が分かりやすいと思います。
→循環バッファ( ++C++; // 未確認飛行 C , 岩永 信之さん)
→キュー(お気楽C言語プログラミング超入門, 広井 誠さん)
製作記事その3で示したとおり、MIDIメッセージの受信はUSART割り込みで行い、MIDIメッセージの解析はメインループ内で行うため、MIDIメッセージ受信と解析のタイミングが同期するとは限りません。そこで受信したMIDIメッセージをバッファに蓄積しておき、解析するタイミングでバッファからデータを取り出します。そのためには、バッファにデータを蓄積した順に取り出す必要があります。
これを実現するのがリングバッファです。リングバッファは配列構造をリング状に(論理的に)接続したもので、イメージは次の通りです。リング状にすることで、データ領域の先頭・終端を任意の位置にすることができるため、使用済みの領域を再利用できます。エコですね。
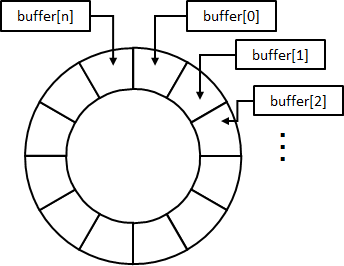
uint8_t型、要素数nのリングバッファ
バッファの蓄積(Enqueue)/取り出し(Dequeue)のイメージ図を下記に示します。この例では、(a)初期状態に対し、(b)[0x90, 0x3C, 0x64]の順に3バイト蓄積、(c)[0x90]の1バイト取りだし、(d)[0x91, 0x3D, 0x65]の順に3バイト蓄積、と操作しています。
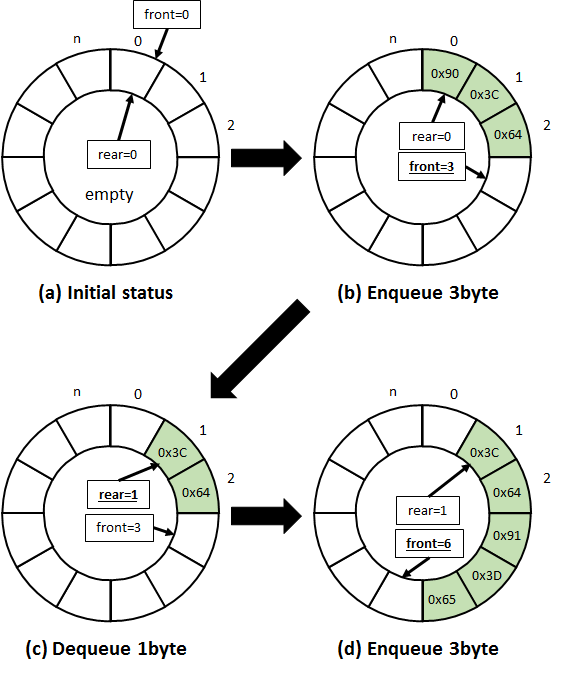
リングバッファの操作:初期状態(a)→3バイト蓄積(b)→1バイト取り出し(c)→3バイト蓄積(d)
ところで、図中のfront, rearは、要素の先頭や終端にアクセスするためのインデックス変数です。図では、(a)~(d)の各処理直後の値を表しており、次のように使います。
- front==rearのとき、バッファが空だと判断。(→上図(a))
- frontがrearの一つ前であるとき、バッファが満杯だと判断。
- 次に蓄積する位置は、frontとする。buffer[front]でアクセス。
- 次に取り出すべき位置は、rearとする。buffer[rear]でアクセス。
このとき、front, rearの値を次のように操作すれば、バッファが適切に動作します。
- バッファの蓄積(Enqueue)と同時にfrontを1増加
- バッファの取り出し(Dequeue)と同時にrearを1増加
- front, rearが要素数nを超えたら0にリセットし、要素数nで循環させる
3.2.実装
まず、バッファの構造体型を定義します。
/*curebuffer.h*/
//uint8_t用リングバッファ構造体
typedef struct{
uint16_t idx_front;
uint16_t idx_rear;
uint16_t length;//バッファ長
uint8_t *buffer;//バッファの先頭アドレス
}RingBufferU8;
一般的に使えるように、バッファを配列としてではなくポインタ(*buffer)として確保しています。後述する初期化処理内で、領域を確保してから使います。
バッファ長はsizeof(buffer)で求まりますが、sizeofによる演算コスト増加を避けるため、初期化時にlengthに代入しておきます。
次に、このRingBufferU8構造体に対して、初期化処理・解放処理・データ蓄積処理・データ取り出し処理の関数を用意します。これらバッファ操作用関数は、curebuffer.h/cにまとめておきます。
/*curebuffer.c*/
//初期化処理
BUFFER_STATUS cureRingBufferU8Init(RingBufferU8 *rbuf, uint16_t buflen)
{
uint32_t i;
cureRingBufferU8Free(rbuf);
rbuf->buffer = (uint8_t *)malloc( buflen * sizeof(uint8_t) );
if(NULL == rbuf->buffer){
return BUFFER_FAILURE;
}
for(i=0; i<buflen; i++){
rbuf->buffer[i] = 0;
}
rbuf->length = buflen;
return BUFFER_SUCCESS;
}
//解放処理
BUFFER_STATUS cureRingBufferU8Free(RingBufferU8 *rbuf)
{
if(NULL != rbuf->buffer){
free(rbuf->buffer);
}
rbuf->idx_front = rbuf->idx_rear = 0;
rbuf->length = 0;
return BUFFER_SUCCESS;
}
//データ蓄積処理
BUFFER_STATUS cureRingBufferU8Enqueue(RingBufferU8 *rbuf, uint8_t *inputc)
{
if( ((rbuf->idx_front +1)&(rbuf->length -1)) == rbuf->idx_rear ){//バッファが満杯
return BUFFER_FAILURE;
}else{
rbuf->buffer[rbuf->idx_front]= *inputc;
rbuf->idx_front++;
rbuf->idx_front &= (rbuf->length -1);
return BUFFER_SUCCESS;
}
}
//データ取り出し処理
BUFFER_STATUS cureRingBufferU8Dequeue(RingBufferU8 *rbuf, uint8_t *ret)
{
if(rbuf->idx_front == rbuf->idx_rear){//バッファが空
return BUFFER_FAILURE;
}else{
*ret = (rbuf->buffer[rbuf->idx_rear]);
rbuf->idx_rear++;
rbuf->idx_rear &= (rbuf->length -1);
return BUFFER_SUCCESS;
}
}
ちなみに、ハイライトした行の演算(front, rearを要素数の範囲で循環させる演算)には、ビット演算を使い高速化しています。例えば下記の2つは同じ結果になりますが、1つ目の方が速いです。ただし要素数を2のべき乗としなければなりません。
//ビット演算(速い)
idx_front &= (length -1);
//条件分岐(遅い)
if( idx_front >= length ){
idx_front -= length;
}
//ビット演算の性質上、要素数lengthには「2のべき乗」という制限あり。
バッファ操作用関数は、MIDI操作用関数群であるcuremidi.h/c内でwrapして使っています。下記のように、cureMidiInit()関数内でバッファ領域を初期化しておき、2.2節のようにcureMidiBufferEnqueue()関数を呼び出すことで、バッファにデータを蓄積できます。
/*curemidi.h, curemidi.c*/
//バッファ長さ
#define MIDIBUFFER_LENGTH (1024)
//バッファ用構造体
RingBufferU8 rxbuf;
//初期化処理
FUNC_STATUS cureMidiInit()
{
//(中略)
if( BUFFER_FAILURE == cureRingBufferU8Init(&rxbuf, MIDIBUFFER_LENGTH) ){
return FUNC_ERROR;
}
//(中略)
return FUNC_SUCCESS;
}
//データ蓄積処理のラップ関数
BUFFER_STATUS cureMidiBufferEnqueue(uint8_t* inputc)
{
return cureRingBufferU8Enqueue(&rxbuf, inputc);
}
//※関数マクロにした方が高速化できると思いますが、読みやすさ優先で…
//他のラップ関数は割愛
ちなみにBUFFER_STATUS, FUNC_STATUSは、それぞれバッファ用、一般関数用のエラーフラグであり、enumで定義しています。コーディングの見やすさのために用意しています。
typedef enum{
BUFFER_FAILURE,BUFFER_SUCCESS
}BUFFER_STATUS;
typedef enum{
FUNC_ERROR,FUNC_SUCCESS
}FUNC_STATUS;
今回はここまで。
次回は、MIDIメッセージの解析処理について紹介します。

コメント